
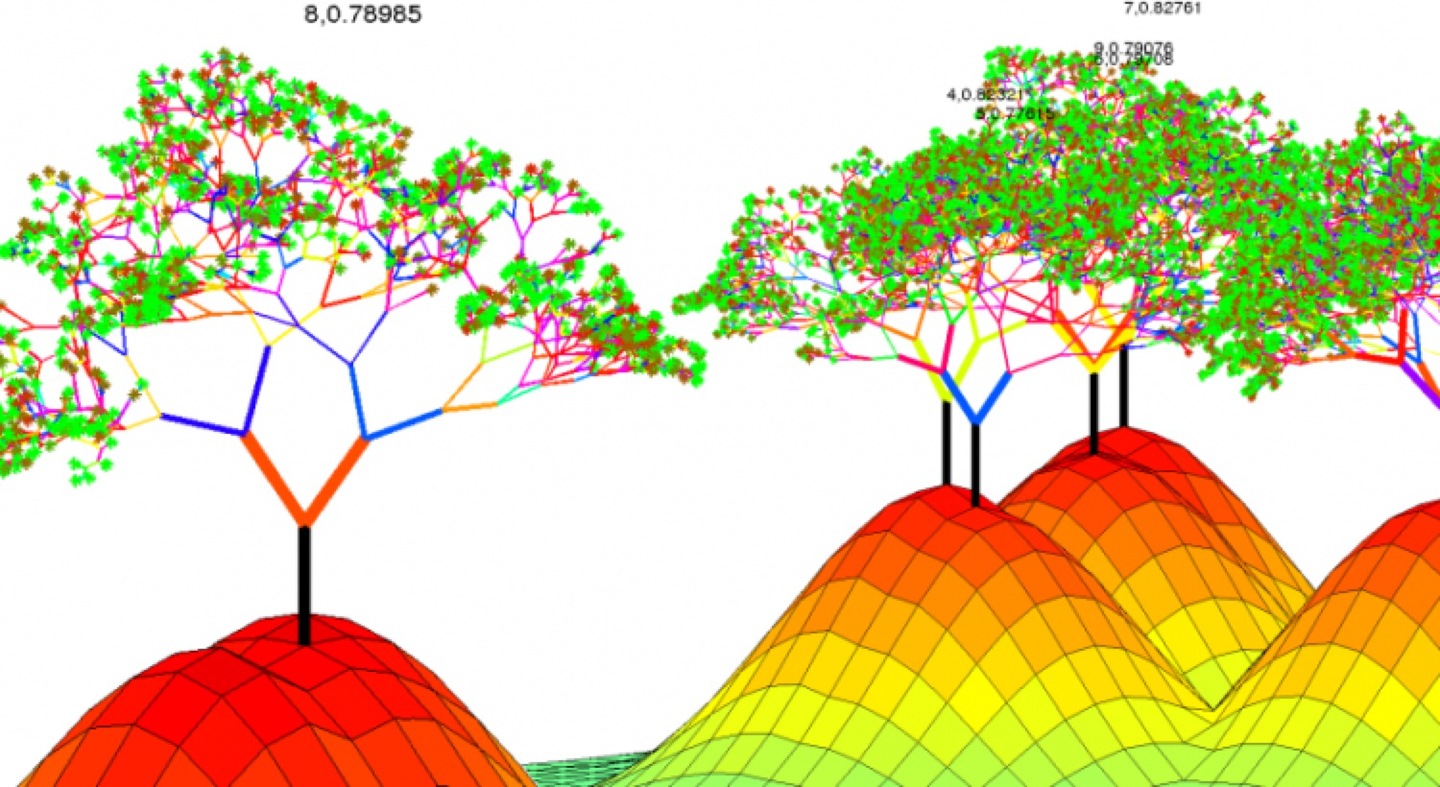
估计阅读时长: 9 分钟https://github.com/xieguigang/sciBASIC 在实际应用的机器学习方法里,GradientTree Boosting (GBDT)是一个在很多应用里都很出彩的技术。XGBoost是一套提升树可扩展的机器学习系统。XGBoost全名叫(eXtreme Gradient Boosting)极端梯度提升。它是大规模并行boosted tree的工具,XGBoost 所应用的算法就是 GBDT(gradient boosting decision tree)的改进,既可以用于分类也可以用于回归问题中。 Order by Date Name […]
估计阅读时长: 23 分钟https://github.com/rsharp-lang/R-sharp 降维是将数据由高维约减到低维的过程而用来揭示数据的本质低维结构。它作为克服“维数灾难”的途径在这些相关领域中扮演着重要的角色。在过去的几十年里,有大量的降维方法被不断地提出并被深入研究,其中常用的包括传统的降维算法如PCA和MDS;流形学习算法如UMAP、t-SNE、ISOMAP、LE以及LTSA等。 Order by Date Name Attachments MNIST-LabelledVectorArray-60000x100 • 230 kB • 876 click 2021年6月27日MNIST-LabelledVectorArray-60000x100Euclidean_Distance • […]
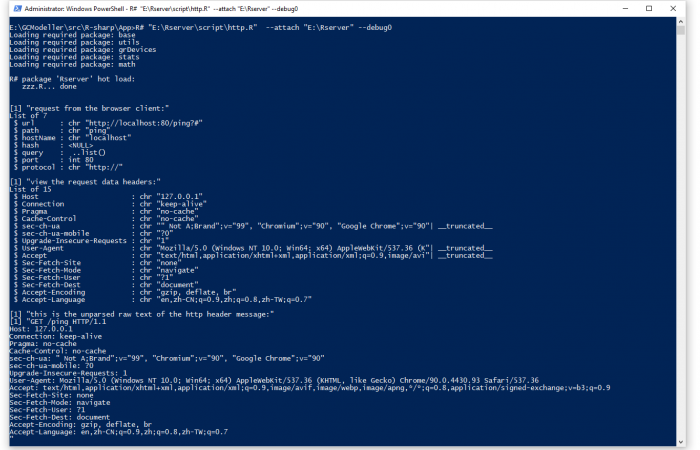
估计阅读时长: 5 分钟https://github.com/rsharp-lang/Rserver 在R语言之中,存在有一个FastRWeb的框架可以将R语言编写的脚本以http服务的方式运行于后台,供其他的语言进行调用。在R#语言之中,我也模仿着R语言之中的FastRWeb框架,创建了一个用于R#语言的web服务的程序包框架。 Order by Date Name Attachments httpr_commandline • 28 kB • 682 click 2021年6月16日http_PUT_test • […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
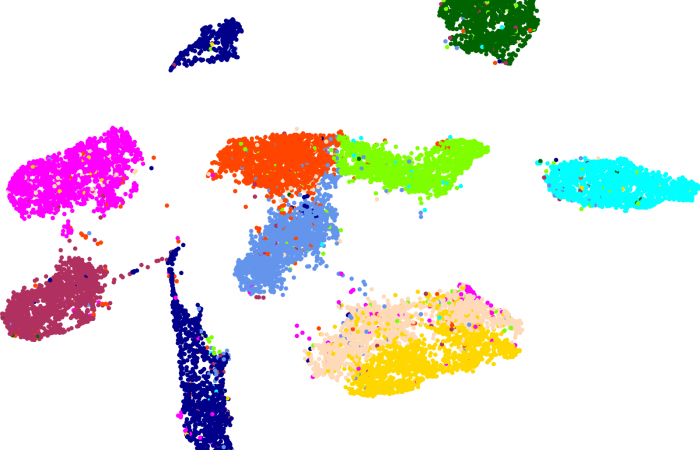
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?