

估计阅读时长: 13 分钟LCA算法是现代宏基因组学分析的核心技术之一,主要用于解决序列比对结果的分类不确定性问题。例如,我们在处理宏基因组测序reads的物种来源分类注释工作的时候,经常会思考一个问题:在宏基因组分析中,一个测序read通常与多个参考序列产生比对结果,这些结果可能指向不同的分类单元。那这条reads最可能的物种分类来源位置是怎样的,怎样可以通过一个算法,基于一系列的物种匹配结果来推断出一个合适的物种来源,既避免过度分类,又保证分类的准确性。 Order by Date Name Attachments family-tree-animal-kingdom • 99 kB • 38 click 2025年12月2日LCA • 245 […]

估计阅读时长: 2 分钟宏基因组学(Metagenomics)通过直接测序环境样本中的全部DNA,从而避免了传统培养方法的局限,使我们能够研究不可培养微生物的多样性。然而,当样本来自宿主相关环境(如人类或小鼠的肠道、土壤等)时,测序数据中不可避免地包含大量宿主自身的DNA序列。这些宿主序列会占据测序读数,增加分析成本,并可能干扰对微生物群落组成的准确推断。因此,在宏基因组数据分析中,去除宿主序列(Host Sequence Removal)是至关重要的预处理步骤。去除宿主序列的算法多种多样,其中基于k-mer的方法因其高效和可扩展性而备受关注。 Attachments Metagenomics • 211 kB • 49 click 2025年11月29日

估计阅读时长: 6 分钟微生物全基因组代谢网络(Genome-scale metabolic model, GEM)模型的发展历史可追溯至20世纪90年代。1994年,Varma和Palsson在《Applied and Environmental Microbiology》期刊上发表了开创性论文,题为"Stoichiometric flux balance models quantitatively predict growth and metabolic by-product […]
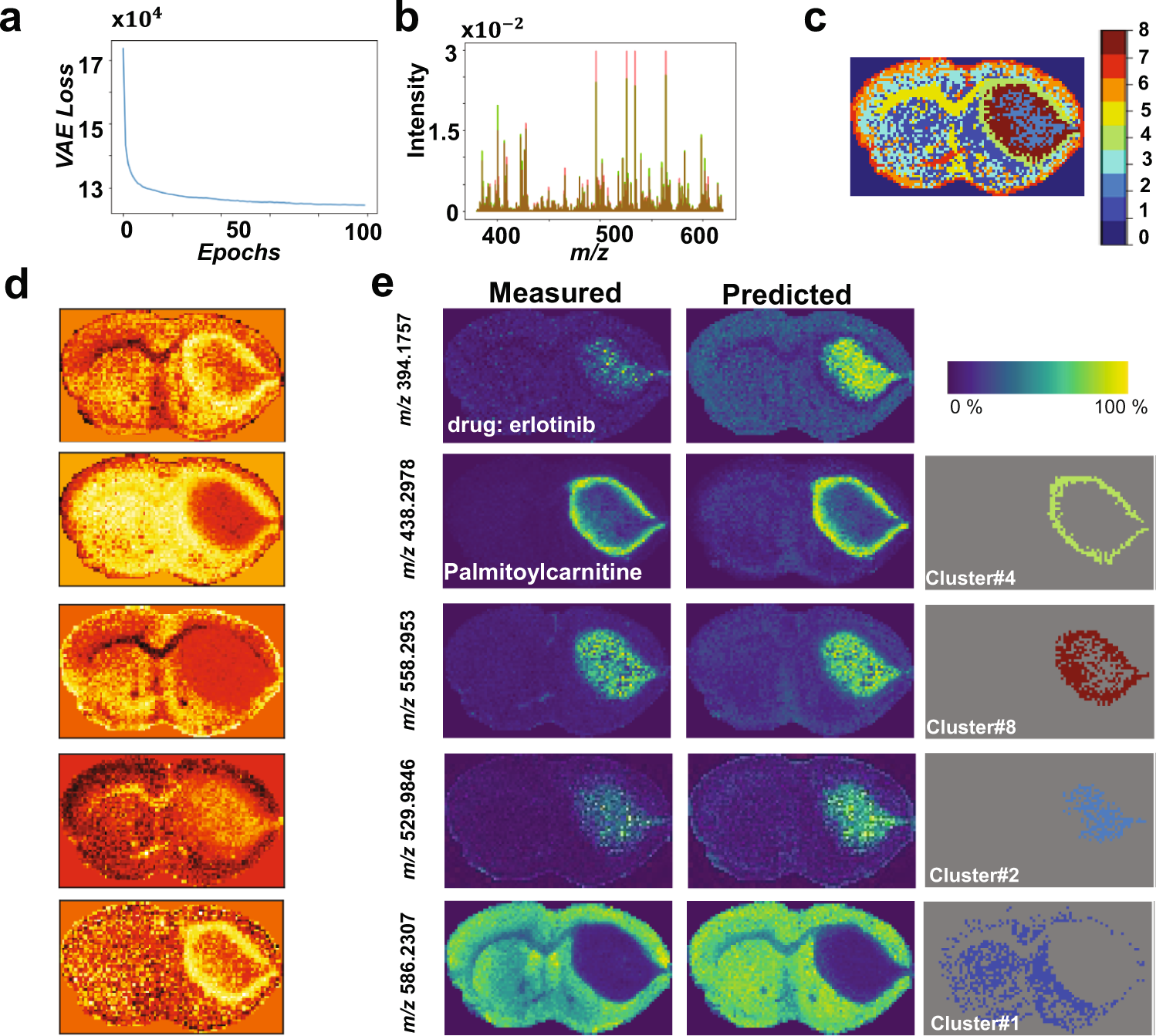
估计阅读时长: 4 分钟基于UMAP工具进行简单的自动化组织分区操作 在这里我们假设已经可以正常的将空间代谢数据导入至MZKit工作站软件之中。假若需要借助于MZKit工作站软件进行切片组织样本的自动化分区操作,相关的功能可以在【MSI Analysis】菜单栏中寻找到。在这里我们打开【Show Map Layer】按钮,选择【UMAP and clustering】功能。 基于降维的组织自动化分区原理 因为降维操作一般是一种特征提取操作,所以经过降维之后,在高维度空间上无法显现的特征,在低维度会呈现出来。在高维度空间散落的相近的数据点,在经过特征提取之后,低维度上会产生相似的特征信息,相互聚集在一簇。这样子我们就可以在低维度空间上通过一些聚类算法讲这些特征进行聚类,最后将聚类特征结果标记到各个散点上的对应的原始成像空间上,我们就可以看见组织分区的结果了。 Abdelmoula, W.M., Lopez, B.GC., Randall, E.C. et […]

估计阅读时长: 7 分钟假若现在有两条Fasta序列放在你面前,现在需要你进行这两条Fasta序列的相似度计算分析。如果对于我而言,大学刚毕业刚入门生物信息学的时候,可能只能够想到通过blast比对的方式进行序列相似性计算分析。基于blast比对方式可以找到生物学意义上的序列相似性结果,但是计算的效率会比较低。假设现在让你使用这些序列进行机器学习建模分析,或者基于传统数学意义上的基于相似度的无监督聚类分析的时候,面对这些长度上长短不一的生物序列数据,可能会比较蒙圈,因为传统的数学分析方法都要求我们分析的目标至少应该是等长的向量数据。 Order by Date Name Attachments Fasta-A • 544 kB • 396 click 2023年6月29日visualize • 45 […]

估计阅读时长: 7 分钟一般而言,进行全基因组的转录表达调控网络的建立,我们需要基于两个数据结果来完成: 目标基因的转录调控位点信息(Motif搜索结果,构成网络之中的节点) 转录调控位点相应的转录调控因子(Motif位点相关的转录调控因子,构成网络之中的边连接) Order by Date Name Attachments Xor • 271 kB • 464 click 2022年6月11日An […]
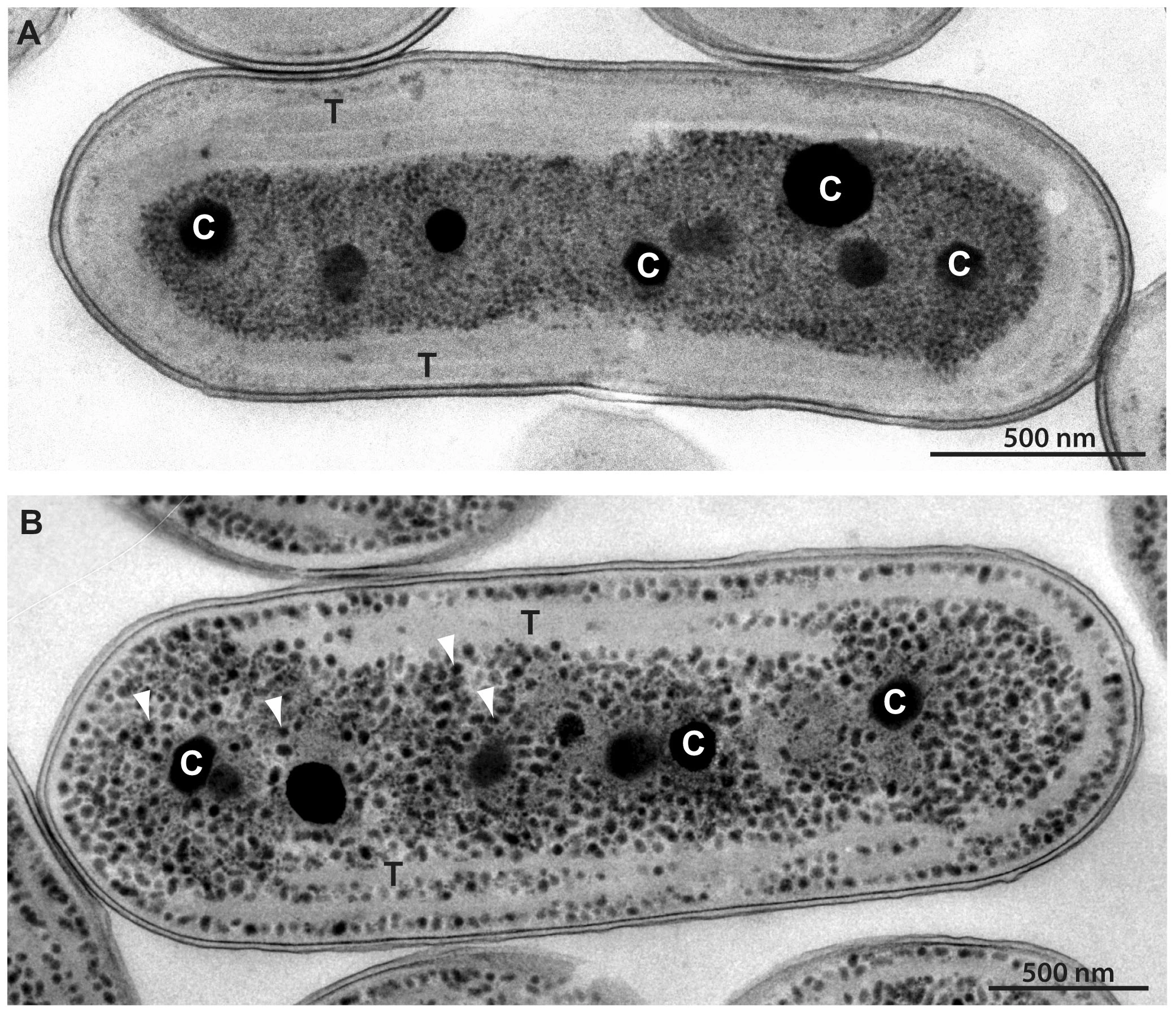
估计阅读时长: 10 分钟https://gcmodeller.org/ 流平衡分析(flux balance analysis)是一种可以用来构建和模拟分析基因组级别的代谢网络的数学方法。流平衡分析是系统生物学(system biology)的一个重要的分析手段。不同于以湿实验的代谢通量分析(metabolic flux analysis, MFA),FBA是用数学方法对代谢网络里的代谢流进行拟合分析。 Order by Date Name Attachments Electron micrographs of […]
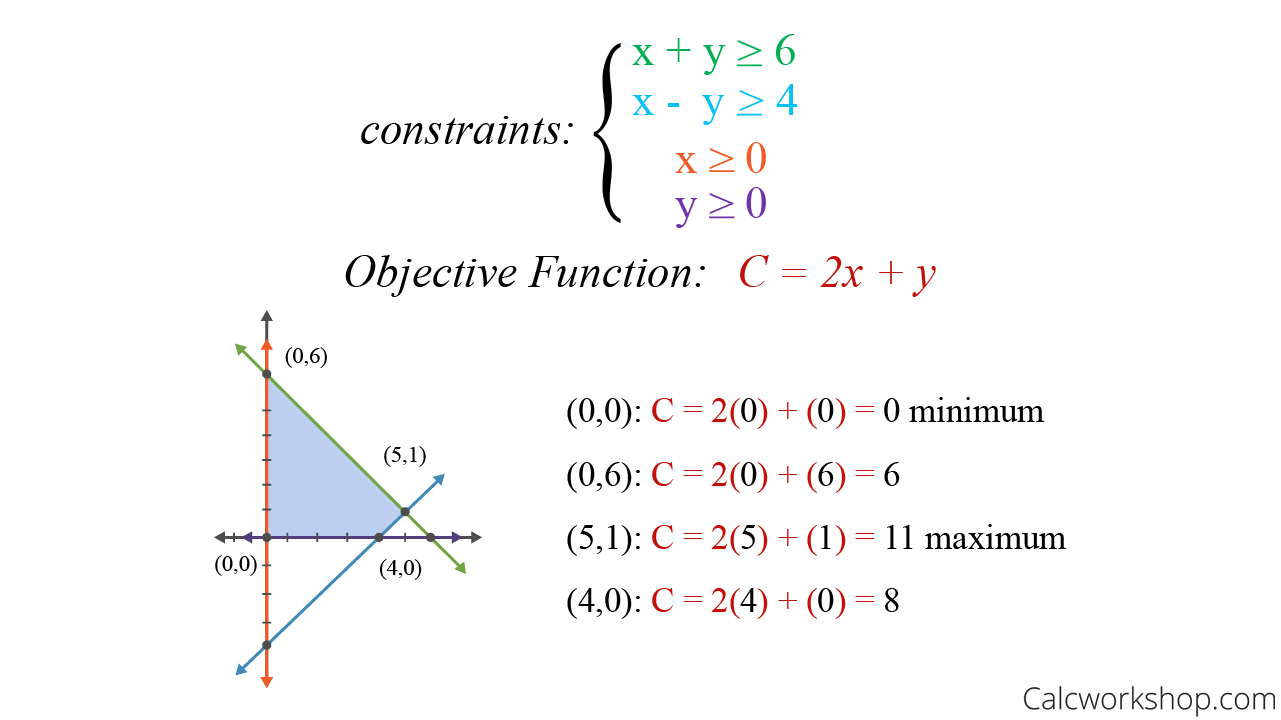
估计阅读时长: 30 分钟https://github.com/xieguigang/sciBASIC/ 线性规划(Linear programming,简称LP)方法起源于20世纪40年代,由美国数学家乔治·丹齐格(George Dantzig)提出,并设计了著名的“单纯形法”。这种优化算法是运筹学中研究较早、发展较快、应用广泛、方法较成熟的一个重要分支,它是辅助人们进行科学管理的一种数学方法。研究线性约束条件下线性目标函数的极值问题的数学理论和方法。通俗点的来讲,就是我们基于这一种数学优化技术,用于在一组线性约束条件下,求解线性目标函数的最大值或最小值(就是在“有限资源”和“一定规则”下,找到“最佳方案”的一种方法)。 Order by Date Name Attachments linear-programming-example • 22 kB • 573 click […]
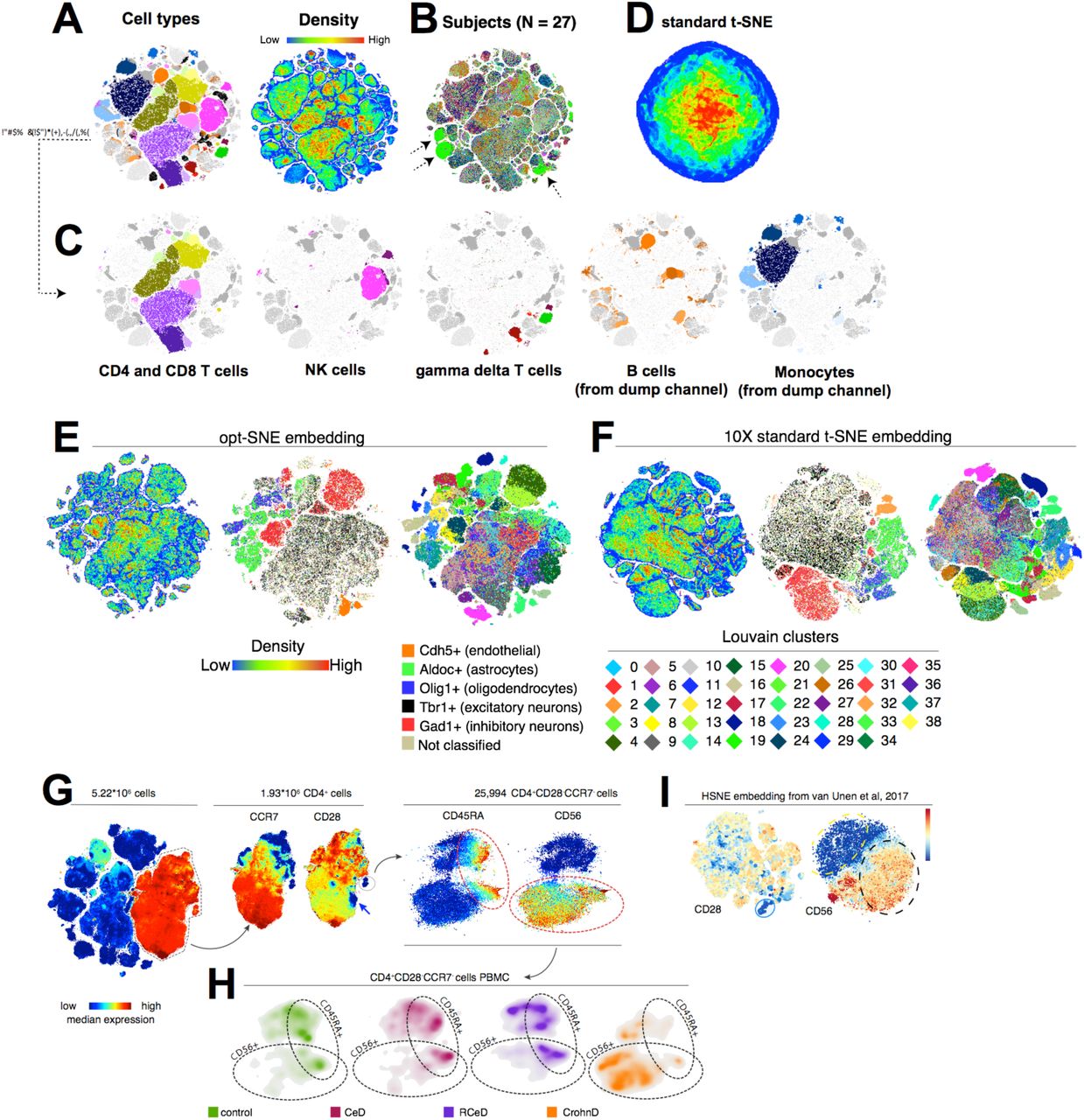
估计阅读时长: 11 分钟PhenoGraph提供了与UMAP类似的算法过程进行单细胞组学数据的细胞分型处理操作。与UMAP方法相比,PhenoGraph并不会产生数据降维效果,仅仅产生数据点Cluster信息。如果需要将数据进行可视化,还需要借助于t-SNE算法将PhenoGraph的分型结果数据投影到一个二维平面上完成。 Order by Date Name Attachments Phenograph-image4 • 200 kB • 490 click 2021年8月9日Automated Optimal Parameters […]

估计阅读时长: 11 分钟https://github.com/xieguigang/sciBASIC Louvain算法是基于模块度的网络节点集群发现算法。该算法在效率和效果上都表现较好,并且能够发现层次性的网络节点集群结构,其优化目标是最大化整个网络集群模块的模块度(Modularity)。 Order by Date Name Attachments graph • 2 MB • 502 click 2021年8月7日Metavirome network […]

Hello blogger, thank you for sharing this post! We process a large number of metagenomic samples, and every time we…
谢博,您好。阅读了您的博客文章非常受启发!这个基于k-mer数据库的过滤框架,其核心是一个“污染源数据库”和一个“基于覆盖度的决策引擎”。这意味着它的应用远不止于去除宿主reads。 我们可以轻松地将它扩展到其他场景: 例如去除PhiX测序对照:建一个PhiX的k-mer库,可以快速剔除Illumina测序中常见的对照序列。 例如去除常见实验室污染物:比如大肠杆菌、酵母等,建一个联合的污染物k-mer库,可以有效提升样本的纯净度。 例如还可以靶向序列富集:反过来想,如果我们建立一个目标物种(比如某种病原体)的k-mer库,然后用这个算法去“保留”而不是“去除”匹配的reads,这不就实现了一个超快速的靶向序列富集工具吗? 这中基于kmer算法的通用性和扩展性可能会是它的亮点之一。感谢博主提供了这样一个优秀的思想原型
It’s laborious to find knowledgeable people on this topic, however you sound like you realize what you’re speaking about! Thanks
WOW, display an image on a char only console this is really cool, I like this post because so much…
确实少有, 这么高质量的内容。谢谢作者。;-) 我很乐意阅读 你的这个技术博客网站。关于旅行者上的金唱片对外星朋友的美好愿望,和那个时代科技条件限制下人们做出的努力,激励人心。