

估计阅读时长: 9 分钟https://github.com/dotvanilla/vanilla WebAssembly是一种运行在浏览器端的二进制程序集文件。和普通的应用程序开发一样,WebAssembly需要基于一定的源代码文本进行编译。这个编译所需要的源代码文本就是WAST文件。 Understanding WebAssembly text format(https://developer.mozilla.org/en-US/docs/WebAssembly/Understanding_the_text_format)
估计阅读时长: 4 分钟https://github.com/dotvanilla/vanilla vanilla编译器项目是我之前开发过的一个实验性质的项目。主要是为了解决在浏览器端的一些高性能计算的需求,例如数据加密和解密,基于WebGL的计算机图形项目,力学物理规律模拟,网络可视化布局计算等。 Order by Date Name Attachments 1_PcKt44c-UZBBTfNBaovxeQ • 49 kB • 680 click 2021年7月8日web-assembly-architecture-xenonstack-3-1 • […]
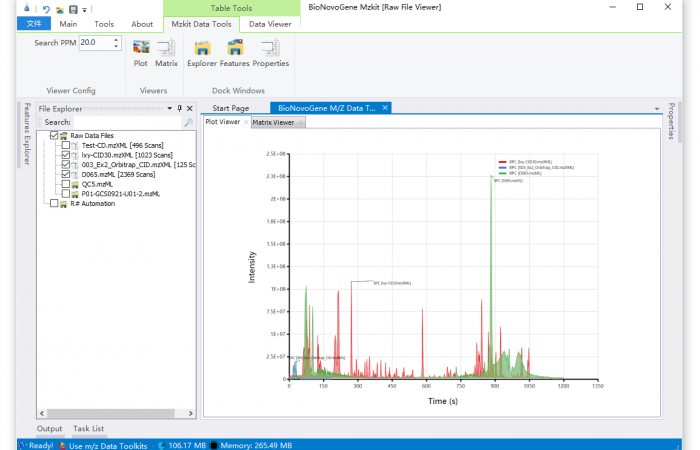
估计阅读时长: 3 分钟https://mzkit.org mzkit软件是我最近开发的一款开源的代谢组学领域内的原始数据文件查看工具。开发mzkit软件的初衷是为了更方便的查看很大的非靶向原始数据文件:因为在开发mzkit软件之前,在开发LCMS的代谢物注释脚本或者建立标准品库数据的时候,如果我想要查看或者导出文件中的一些质谱图碎片信息,会需要通过R环境之中的xcms程序包编程来完成。通过R脚本来查看原始数据文件,非常的不方便。所以就有了mzkit软件项目的诞生。 Order by Date Name Attachments BPC_overlay • 114 kB • 781 click 2021年7月1日LCMS_scanTree • […]
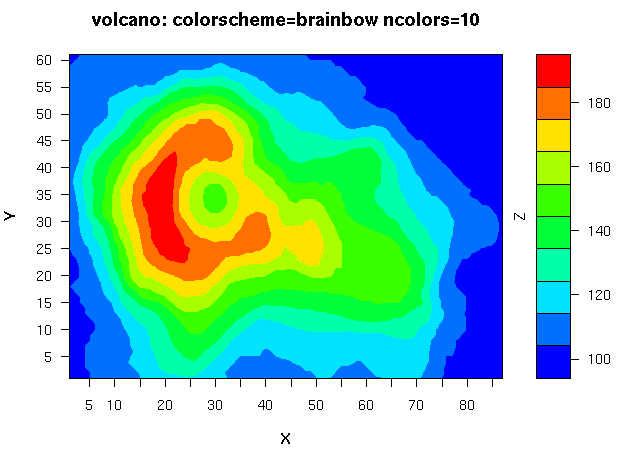
估计阅读时长: 16 分钟https://github.com/xieguigang/sciBASIC 等高线指的是地形图上高程相等的相邻各点所连成的闭合曲线。把地面上海拔高度相同的点连成的闭合曲线,并垂直投影到一个水平面上,并按比例缩绘在图纸上,就得到等高线。 Order by Date Name Attachments 1_Contour • 487 kB • 886 click 2021年6月30日Ms1Contour • […]
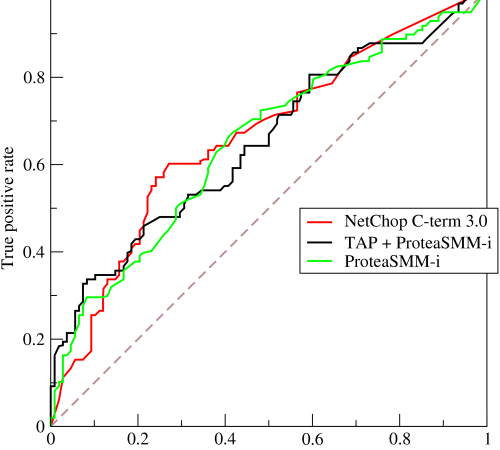
估计阅读时长: 8 分钟https://github.com/rsharp-lang/R-sharp 对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签。如神经网络得到诸如0.5,0.8这样的分类结果。这时,我们人为取一个阈值,比如0.4,那么小于0.4的归为0类,大于等于0.4的归为1类,可以得到一个分类结果。同样,这个阈值我们可以取0.1或0.2等等。 Order by Date Name Attachments ROC • 221 kB • 787 click 2021年6月28日Roccurves • […]
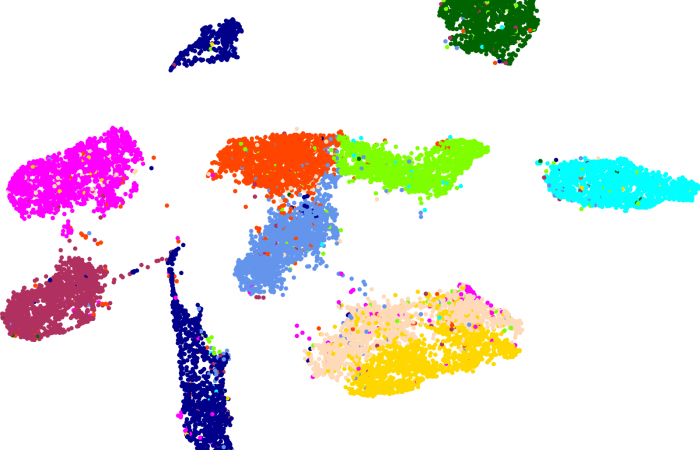
估计阅读时长: 23 分钟https://github.com/rsharp-lang/R-sharp 降维是将数据由高维约减到低维的过程而用来揭示数据的本质低维结构。它作为克服“维数灾难”的途径在这些相关领域中扮演着重要的角色。在过去的几十年里,有大量的降维方法被不断地提出并被深入研究,其中常用的包括传统的降维算法如PCA和MDS;流形学习算法如UMAP、t-SNE、ISOMAP、LE以及LTSA等。 Order by Date Name Attachments MNIST-LabelledVectorArray-60000x100 • 230 kB • 878 click 2021年6月27日MNIST-LabelledVectorArray-60000x100Euclidean_Distance • […]
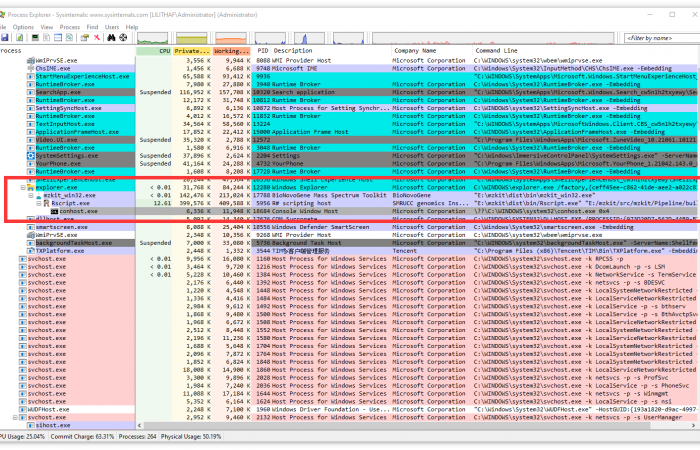
估计阅读时长: 9 分钟https://github.com/xieguigang/sciBASIC 应用程序管线模式就是我们将执行时间比较长,计算任务比较重量级的代码放到一个新的子进程之中执行。通过子进程进行任务执行的应用程序管线模式在各个操作系统上的大型应用程序中都会涉及到。 Order by Date Name Attachments processexplorer • 206 kB • 668 click 2021年6月26日vs_pipeline • […]
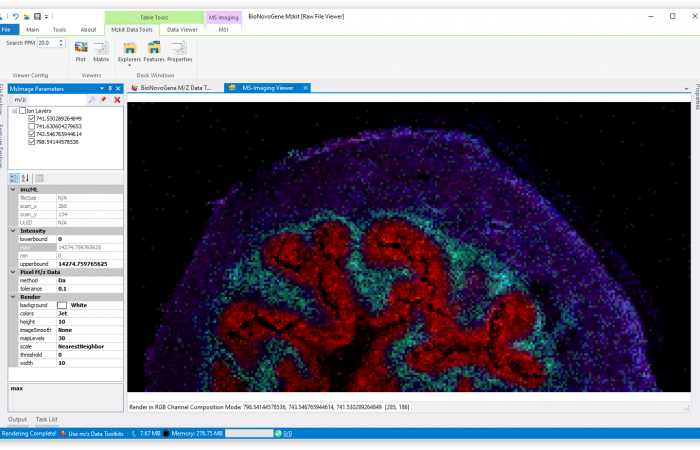
估计阅读时长: 3 分钟http://mzkit.org/ 质谱成像是以质谱技术为基础的成像方法,该方法通过质谱直接扫描生物样品成像,可以在同一张组织切片或组织芯片上同时分析数百种分子的空间分布特征。 Order by Date Name Attachments HR2MSI mouse urinary bladder S096 - optical image • […]
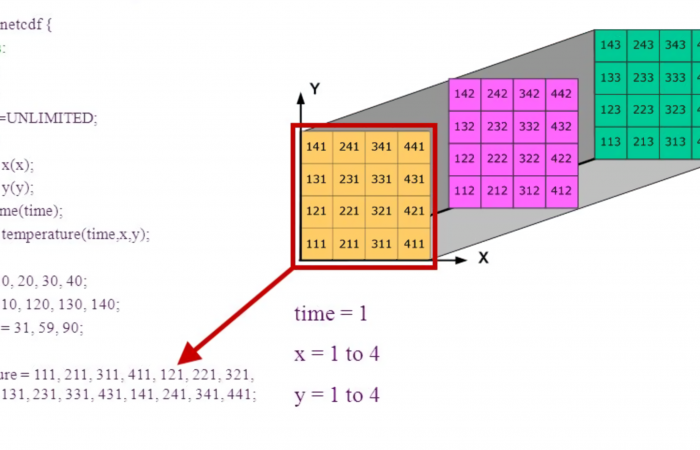
估计阅读时长: 15 分钟https://github.com/xieguigang/Darwinism NetCDF文件格式(Network Common Data Format)是一种以network byteorder进行编码的CDF数据文件格式。其广泛应用于大气科学、水文、海洋学、环境模拟、地球物理等诸多数据科学计算分析领域内的数据存储。 Order by Date Name Attachments netcdf • 2 MB • […]

估计阅读时长: 8 分钟https://github.com/xieguigang/Darwinism 对于LINQ数据查询引擎而言,其可以接收任意类型的数据源,进行数据查询。只要存在有相对应的数据源驱动程序即可。 Order by Date Name Attachments sqlite • 18 kB • 739 click 2021年6月19日sqlite-contents • […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?