
文章阅读目录大纲
LDA(Latent Dirichlet Allocation,潜在狄利克雷分配)是一种用于发现文档集合中潜在主题的生成式概率模型。它假设文档是由多个主题混合而成的,而每个主题又是通过一定的概率分布选择词语生成的。LDA模型包含词、主题和文档三层结构,通过概率生成过程模拟文档的形成。Gibbs LDA 的核心在于使用吉布斯采样方法来推断这些隐藏的主题分布。
Gibbs LDA 算法原理与代码实现
LDA模型回顾:生成文档的“上帝掷骰子”过程
LDA模型假设文档的生成过程可以类比为一个“上帝掷骰子”的游戏。在这个过程中,上帝(模型)并非直接写出文章,而是通过一系列概率步骤“生成”文档中的每个词。具体而言,LDA模型的生成过程可以概括如下:
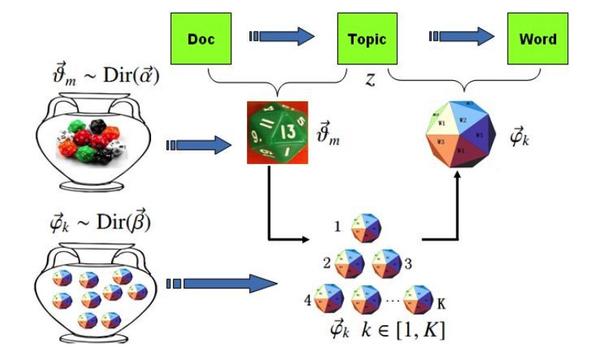
- 为每个主题生成词分布:模型首先为语料库中的每个主题生成一个“词骰子”。这个骰子的每一面对应词汇表中的一个词,但不同词出现的概率不同。换言之,每个主题都有一个对应的词概率分布,我们将其记作$\phi_k$(其中$k$为主题编号),它表示在主题$k$下各个词出现的概率。由于这是一个多项式分布的参数,LDA为其引入了Dirichlet先验分布,以避免过拟合并提供平滑。Dirichlet分布是多项式分布的共轭先验,这一性质保证了在推断时的数学便利性。因此,形式上,我们假设$\phi_k \sim \text{Dirichlet}(\beta)$,其中$\beta$是超参数。
- 为每篇文档生成主题分布:接下来,对于语料库中的每篇文档,模型生成一个“主题骰子”。这个骰子的每一面对应一个主题编号,表示该文档可能包含的主题。每篇文档的主题分布(即文档中各主题出现的概率)记作$\theta_d$(其中$d$为文档编号)。同样地,LDA假设$\theta_d$服从Dirichlet分布,即$\theta_d \sim \text{Dirichlet}(\alpha)$,其中$\alpha$是另一个超参数。这相当于为每篇文档的主题比例提供了一个先验分布,认为文档的主题构成并非固定不变,而是具有一定的随机性。
- 生成文档中的每个词:有了文档的主题骰子和各个主题的词骰子,文档中每个词的生成就变成了一个两步的掷骰子过程:
- 选择主题:首先,投掷该文档对应的“主题骰子”,随机抽取一个主题编号$z$。这个过程相当于根据文档的主题分布$\theta_d$,以一定概率选择一个主题。例如,某文档的主题分布可能是{教育:0.5, 经济:0.3, 交通:0.2},那么抽取“教育”主题的概率就是0.5。
- 选择词语:然后,根据抽到的主题编号$z$,投掷对应的“词骰子”$\phi_z$,从中随机抽取一个词$w$作为文档中下一个词。这意味着,一旦确定了主题,我们实际上是在该主题的词分布下抽取词语。例如,如果抽到的主题是“教育”,那么接下来就在“教育”主题对应的词分布下抽取词,该分布可能赋予“大学”一词较高的概率,因此“大学”这个词更有可能被选中。
上述“选主题-选词语”的过程重复进行,每生成一个词就记录下来,直到文档达到预定的长度。这样,通过多次重复掷骰子,模型就“写”出了一篇文档。重复此过程$M$次,即可生成包含$M$篇文档的整个语料库。
这一生成过程形象地展示了LDA模型背后的假设:一篇文档是由多个主题构成的,文档中的每个词都源自某个主题。主题是隐含的变量,我们观察到的是文档中的词,而模型的目标就是根据这些词去反推文档的主题分布以及每个主题的词分布。这正是LDA模型在文本分析中应用的核心:从文档集中自动发现潜在的主题结构。
Gibbs LDA 完整算法流程
LDA模型的参数估计并非易事。直接求取模型参数的最大似然估计需要计算文档的边际概率,这涉及对所有可能的隐含主题分配进行求和,计算复杂度极高,在数学上是不可行的。因此,需要借助近似推断方法来估计模型参数。常见的两种求解LDA的方法是变分推断(Variational Inference)和马尔可夫链蒙特卡洛(MCMC)方法。其中,Gibbs采样是MCMC方法中应用广泛的一种,它通过构造一个马尔可夫链,使链的平稳分布就是我们想要的后验分布,从而近似地抽取样本。
Gibbs采样特别适合用于LDA这类带有隐含变量的模型。其基本思想是:通过迭代地对每个隐含变量(在LDA中即每个词的主题分配)进行采样,逐步逼近后验分布。相比于变分推断需要构建一个近似的分布族,Gibbs采样实现起来更加直观,易于编程,并且由于它直接对隐变量进行采样,通常能够更快地收敛。此外,Gibbs采样天然地支持并行化,可以方便地扩展到大规模数据集上。
在LDA模型中,我们需要估计的隐含变量包括:每篇文档的主题分布$\theta_d$、每个主题的词分布$\phik$以及语料库中每个词对应的主题分配$z{dn}$。然而,Gibbs采样并不直接估计$\theta_d$和$\phik$这些连续变量,而是采取一种“坍塌”(Collapsed)的策略,将它们积分掉,只对离散的主题分配$z{dn}$进行采样。这一策略利用了Dirichlet-multinomial共轭性质,使得我们可以推导出一个条件概率公式,用于在已知其他所有词的主题分配的情况下,计算某个词属于各个主题的概率。通过反复应用这个公式进行采样,我们最终可以得到每个词的主题分配,进而统计得到$\theta_d$和$\phi_k$的估计。
┌─────────────────────────────────────────────────────────────────────────────┐
│ 输入: 文档集合 D = {d₁, d₂, ..., dₘ} │
└─────────────────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────────────────┐
│ 步骤1: 预处理 (DocumentLoader) │
│ • 分词、过滤停用词 │
│ • 构建词汇表 V (Vocabulary) │
│ • 文档转换为词ID序列 │
└─────────────────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────────────────┐
│ 步骤2: 初始化 (initialState) │
│ • 随机初始化主题分配: z[m][n] ~ Uniform(1, K) │
│ • 初始化计数器: nw, nd, nwsum, ndsum │
└─────────────────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────────────────┐
│ 步骤3: Gibbs采样主循环 (iterations = 1 to ITERATIONS) │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ for each document m: │ │
│ │ for each word n in document m: │ │
│ │ ┌───────────────────────────────────────────────────────────────┐ │ │
│ │ │ 1. 移除计数: nw[w][z_old]--, nd[m][z_old]-- │ │ │
│ │ │ 2. 计算条件概率: │ │ │
│ │ │ p(k) ∝ (n^w_{k,w}+β)/(n^w_k+Vβ) × (n^d_{m,k}+α)/(n^d_m+Kα)│ │ │
│ │ │ 3. 采样新主题: z_new ~ Multinomial(p) │ │ │
│ │ │ 4. 更新计数: nw[w][z_new]++, nd[m][z_new]++ │ │ │
│ │ └───────────────────────────────────────────────────────────────┘ │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ if iteration > BURN_IN and iteration % SAMPLE_LAG == 0: │ │
│ │ 累积参数估计: thetasum += θ, phisum += φ │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────────────────┐
│ 步骤4: 参数估计 │
│ θ_mk = (n^d_{m,k} + α) / (n^d_m + K×α) [文档-主题分布] │
│ φ_kv = (n^w_{k,v} + β) / (n^w_k + V×β) [主题-词分布] │
└─────────────────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────────────────┐
│ 步骤5: 结果解释 (LdaInterpreter) │
│ • 对每个主题,按φ概率排序,输出top-N词 │
│ • 得到可解释的主题列表 │
└─────────────────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────────────────┐
│ 输出: │
│ • θ: M×K矩阵,每行表示一个文档的主题分布 │
│ • φ: K×V矩阵,每行表示一个主题的词分布 │
│ • 主题词列表: {主题1: [词1, 词2, ...], 主题2: [...], ...} │
└─────────────────────────────────────────────────────────────────────────────┘在上面所初步展示的整个gibbs LDA算法流程终所涉及到的关键超参数如下所示:
| 参数 | 说明 |
|---|---|
| K | 主题数量(通常需要调参,常用10-100) |
| α | 文档-主题先验参数,控制文档中主题分布的稀疏性 |
| • α越大:文档倾向于包含更多主题(分布更均匀) | |
| • α越小:文档倾向于少数主题(分布更稀疏) | |
| • 典型值: 50/K 或 2.0 | |
| β | 主题-词先验参数,控制主题中词分布的稀疏性 |
| • β越大:主题包含更多词(分布更均匀) | |
| • β越小:主题集中于少数词(分布更稀疏) | |
| • 典型值: 0.01 或 0.5 | |
| ITERATIONS | 总迭代次数(典型值: 1000-2000) |
| BURN_IN | 预热期,丢弃前面的迭代(典型值: 100-500) |
| SAMPLE_LAG | 采样间隔,每隔多少次迭代采样一次(典型值: 10-100) |
在上面所展示出来的Gibbs LDA的算法流程虽然看起来比较复杂,但是总结下来,其核心思想比较简单。可以类比为一个“协调投票”的过程。想象一下,我们把文档中的每个词都想象成一个小人,它们各自当前属于某个主题阵营。Gibbs采样的过程就是让每个小人轮流站出来,根据周围同伴的选择和自身特征,重新决定自己应该属于哪个阵营。
具体来说,当轮到某个词小人投票(更新主题)时,它会考虑两个方面:
- 同伴的影响:它看看自己的“文档家园”里,其他词小人大多属于哪个主题。如果大部分同伴都归属于主题A,那么它倾向于也投靠主题A。这对应于公式中的文档主题分布部分,即文档中已有的主题分布情况。
- 自身特征:它也看看自己的“词汇特征”。如果它本身是某个典型的主题词汇(比如“宇宙”这个词),那么它更倾向于选择与自己语义相近的主题。这对应于公式中的主题词分布部分,即该词在不同主题下的典型程度。
综合这两方面,词小人会计算自己归属各个主题的“得票概率”,然后根据这个概率随机选择一个新主题。这个过程不断重复,每个词小人都有机会重新投票,最终整个系统会达到一种相对稳定的状态。在这种状态下,每个文档的主题构成和每个主题的词汇构成都趋于合理,反映出语料库中潜在的主题结构。
通过这种“投票”机制,Gibbs采样巧妙地利用了局部信息(文档内部其他词的主题和词在不同主题下的分布)来推断全局的隐含结构。它不需要复杂的优化算法,而是通过简单的迭代采样,逐步逼近模型的后验分布。这种直观的迭代优化过程,使得LDA能够自动地发现文档集中的隐含主题,并且对用户而言具有较好的可解释性。
基于上面的流程代码中所涉及到的参数和矩阵数据,我们可以构建出如下所示的吉布斯LDA基础模块代码作为基础:
' 核心数据结构
Public Class LdaGibbsSampler
Friend documents As Integer()() ' 文档数据(M个文档)
Friend V As Integer ' 词汇表大小
Friend K As Integer ' 主题数量
' 超参数
Friend alpha As Double = 2.0 ' 文档-主题先验参数
Friend beta As Double = 0.5 ' 主题-词先验参数
' 隐变量
Friend z As Integer()() ' 主题分配 z[m][n]
' 计数器
Friend nw As Integer()() ' nw[w][k]: 词w分配给主题k的次数
Friend nd As Integer()() ' nd[m][k]: 文档m中主题k的词数
Friend nwsum As Integer() ' nwsum[k]: 主题k的总词数
Friend ndsum As Integer() ' ndsum[m]: 文档m的总词数
End Class在上面所展示的基础算法模块中,由4个主要的矩阵对象:
nw[w][k]: nₖᵂ(ʷ)nd[m][k]: nₖᴰ⁽ᵐ⁾nwsum[k]: nₖndsum[m]: nₘ
初始化
我们在加载了所需要进行分析的文档数据之后,首先会需要对上面所示的数据进行初始化。整个初始化阶段主要分为两个步骤:
- 随机初始化每个词的主题分配 z[m][n] ~ Uniform(1, K)
- 根据初始分配更新计数器
在这个初始化步骤中,我们会对语料库中每一篇文档的每一个词,随机赋予一个主题编号$z_{dn}$。这相当于为每个词随机选择一个初始主题,虽然初始分配可能不准确,但它为后续迭代提供了起点。
Private Sub initialState(K As Integer)
Dim lM = documents.Length
' 分配计数器内存
nw = RectangularArray.Matrix(Of Integer)(V, K) ' V×K矩阵
nd = RectangularArray.Matrix(Of Integer)(lM, K) ' M×K矩阵
nwsum = New Integer(K - 1) {} ' K维向量
ndsum = New Integer(lM - 1) {} ' M维向量
' 随机初始化主题分配
z = New Integer(lM - 1)() {}
For m As Integer = 0 To lM - 1
lN = documents(m).Length
z(m) = New Integer(lN - 1) {}
For n As Integer = 0 To lN - 1
topic = randf.NextInteger(K) ' 随机选择主题
z(m)(n) = topic
' 更新计数器
nw(documents(m)(n))(topic) += 1 ' 词计数
nd(m)(topic) += 1 ' 文档主题计数
nwsum(topic) += 1 ' 主题总计数
Next
ndsum(m) = lN ' 文档总词数
Next
End Sub在Gibbs LDA算法中,初始化阶段是构建马尔可夫链蒙特卡洛(MCMC)采样起点的关键步骤。这一阶段的主要任务是为语料库中的每一个词语分配一个初始的主题,并建立相应的计数器系统,为后续的迭代采样提供数据基础。
在代码实现中,这一过程主要集中在 LdaGibbsSampler 类的 initialState 方法中。首先,算法需要分配内存来存储核心的计数器矩阵。代码中定义了四个关键的计数器变量:nw(词-主题计数矩阵)、nd(文档-主题计数矩阵)、nwsum(主题词数统计向量)和 ndsum(文档词数统计向量)。其中,nw 是一个维度为 V×K 的矩阵(V 为词汇表大小,K 为主题数),用于记录每个词被分配到每个主题的次数;nd 是一个维度为 M×K 的矩阵(M 为文档数),用于记录每篇文档中属于每个主题的词数。
核心初始化逻辑通过双重循环实现:外层循环遍历所有文档,内层循环遍历文档中的每一个词语。对于当前处理的词语,算法通过随机函数 randf.NextInteger(K) 在 0 到 K−1 的范围内随机分配一个主题编号。这种等概率的随机分配旨在确定马尔可夫链的初始状态。在分配完主题后,代码立即更新上述四个计数器。例如,若文档 m 中的第 n 个词 w 被分配了主题 k,则 nw[w][k] 自增 1,nd[m][k] 自增 1,nwsum[k] 自增 1,同时 ndsum[m] 记录该文档的总词数。
从数学角度看,这一过程对应于设定隐变量 z(主题分配)的初始状态 z(0) 。由于Gibbs采样是基于迭代收敛的,初始状态的选取理论上不影响最终收敛结果,但合理的初始化可以加快收敛速度。代码中采用的随机初始化是最基础的策略,它构建了一个完整的初始状态空间,使得后续的条件概率计算有据可依。初始化完成后,系统进入准备就绪状态,所有的统计量均已建立,等待进入主循环进行迭代更新。
迭代采样主循环
迭代采样主循环是Gibbs LDA算法的核心驱动力,其目的是通过反复迭代更新每个词语的主题分配,使马尔可夫链逐渐收敛到目标分布(即后验分布)。在代码中,这一逻辑主要位于 LdaGibbsSampler 类的 gibbs 方法和 GibbsSamplingTask 类的 Solve 方法中。
主循环通过一个 For Each 循环控制,迭代次数由 ITERATIONS 常量决定(默认为1000次)。每一次迭代,算法都会遍历语料库中的所有文档和文档中的所有词语。代码利用了并行计算优化性能,通过 sampling 方法调用 GibbsSamplingTask,在多线程环境下对不同文档进行并行处理,但在逻辑上仍是针对每一个词语进行操作。
具体的采样过程可以分为三个步骤:移除计数、概率采样、更新计数。在 GibbsSamplingTask.Solve 方法中,首先执行“移除计数”操作。对于当前正在处理的词语,算法先将其从现有的统计计数中剔除。具体来说,如果该词语当前的主题为 k,则将 nw[w][k]、nd[m][k]、nwsum[k] 和 ndsum[m] 均减去 1。这一步非常关键,它确保了在计算该词语属于某个主题的条件概率时,不包含其自身的贡献,满足Gibbs采样的条件独立性假设。
接下来是“概率采样”阶段。算法调用 gibbs_sampling 函数,利用当前更新后的计数器,计算该词语属于各个主题的概率分布,并根据该分布随机采样新的主题。最后是“更新计数”阶段,一旦确定了新的主题 k new,算法立即将相关计数器加 1,将词语重新纳入统计体系。
此外,代码中还实现了预热和采样间隔机制。在 gibbs 方法中,通过 BURN_IN 变量设定预热期(默认100次迭代)。在预热期内的迭代结果不会被记录,因为此时马尔可夫链尚未收敛,样本质量较差。只有当迭代次数超过 BURN_IN 且满足 SAMPLE_LAG 间隔时,系统才会调用 update_params 方法保存当前的参数统计量。这种机制有效地过滤了不稳定的前期状态,并减少了样本之间的自相关性,确保了最终模型参数的准确性。
┌─────────────────────────────────────────┐
│ Gibbs采样主循环 │
├─────────────────────────────────────────┤
│ for iteration = 1 to ITERATIONS: │
│ ├─ for 每个文档 m: │
│ │ └─ for 每个词 n: │
│ │ ├─ 移除当前词的主题计数 │
│ │ ├─ 采样新主题 p(z|z₋ᵢ,w) │
│ │ └─ 更新计数器 │
│ ├─ if iteration > BURN_IN: │
│ │ └─ 累积参数估计 │
└─────────────────────────────────────────┘LDA(Latent Dirichlet Allocation,潜在狄利克雷分配)是一种生成式的概率图模型,其目的是从大规模文档集合中发现潜在的主题结构。在提供的代码中,LdaGibbsSampler 类不仅实现了采样算法,其数据结构本身也映射了LDA的模型架构。
LDA模型假设文档是主题的随机混合,而主题是词汇的随机混合。从生成过程的角度理解,对于每一篇文档 m,模型首先根据参数为 α 的Dirichlet分布生成一个主题分布 θm(代码中对应属性 Theta)。然后,对于文档中的每一个词位,模型首先根据 θm 抽取一个主题z,接着根据该主题对应的词分布
φz (代码中对应属性 Phi)抽取具体的词汇。代码中的 alpha 和 beta 分别控制着文档-主题分布和主题-词分布的稀疏程度:较大的 α 意味着文档倾向于包含多个主题,较小的 α 则意味着文档集中于少数主题。
在代码实现中,Vocabulary 类和 Corpus 类构成了模型的输入层,负责将文本转化为计算机可处理的索引矩阵。Vocabulary 类维护了词汇与ID的双向映射,是模型的基础字典。Corpus 类则封装了文档集合,将其转换为二维的整数数组 documents,其中每个整数代表词汇表中的一个词。
LDA模型的推断目标是求解隐变量(主题分配 z)的后验分布。然而,这个后验分布是难以直接计算的。代码中的 LdaGibbsSampler 采用Gibbs采样方法,这是一种特殊的马尔可夫链蒙特卡洛(MCMC)方法。它不直接计算复杂的积分,而是通过构建一条马尔可夫链,使其平稳分布为目标后验分布。通过在状态空间中不断游走并按照条件概率更新状态,最终收集的样本可以近似看作是从后验分布中抽取的。代码中的 z 矩阵就是记录每一个词语主题分配的隐变量矩阵,它的演化过程直观地展示了模型从混乱到有序的学习过程。
LDA模型的生成过程如下所示:
1. 对每个主题 k = 1...K:
采样主题-词分布: φ_k ~ Dirichlet(β)
2. 对每个文档 m = 1...M:
a. 采样文档-主题分布: θ_m ~ Dirichlet(α)
b. 对每个词 n = 1...N_m:
i. 采样主题: z_mn ~ Multinomial(θ_m)
ii. 采样词: w_mn ~ Multinomial(φ_{z_mn})LDA概率图模型
LDA是一个三层贝叶斯模型:
α (超参数)
↓
θ_m ~ Dirichlet(α) [文档m的主题分布]
↓
z_mn ~ Multinomial(θ_m) [文档m第n个词的主题]
↓
w_mn ~ Multinomial(φ_{z_mn}) [生成的词]
↑
φ_k ~ Dirichlet(β) [主题k的词分布]
↑
β (超参数)图模型表示:
文档层 → 主题层 → 词层
Gibbs采样的条件概率公式
Gibbs采样的条件概率公式是整个LDA算法的灵魂,它决定了如何根据当前的文档和词汇环境推断词语的主题归属。在代码中,这一核心算法位于 GibbsSamplingTask 类的 gibbs_sampling 函数中。Gibbs采样算法的关键在于推导出条件概率分布$p(zi = k | \mathbf{w}, \mathbf{z}{\neg i})$,即在已知语料库中除第$i$个词以外所有词的主题分配时,第$i$个词的主题为$k$的概率。这个概率就是我们每次采样更新的依据。
该函数实现了LDA模型中著名的Gibbs采样更新公式。数学上,该公式描述了在给定其他所有词语的主题分配 z−i 和观测到的语料库 w 的条件下,第 i 个词语属于主题 k 的条件概率 P(zi =k∣z−i,w)。公式由两部分乘积组成:第一部分反映的是词语与主题的关联程度,第二部分反映的是主题与文档的关联程度。
对应到代码逻辑中,公式的计算体现在以下几行核心代码:
p(K) = (nw(K) + gibbs_pars.beta) / (nwsum(K) + gibbs_pars.voca_size * gibbs_pars.beta)
*
(nd(K) + gibbs_pars.alpha) / (ndsum(m) + gibbs_pars.K * gibbs_pars.alpha)这里,nw(K) 代表了除去当前词后,词汇表中该词在主题 K 中出现的次数;nwsum(K) 是主题 K 包含的总词数;beta 是Dirichlet先验参数。这部分计算对应于公式中的 (nk,w−i+β)/(nk−i+Vβ) ,直观理解是:如果一个词在主题 K 中出现得越频繁,且主题 K 的规模适中,那么当前词属于该主题的概率就越大。
公式的后半部分涉及文档层面的统计。nd(K) 是当前文档中分配给主题 K 的词数(除去当前词),ndsum(m) 是文档 m 的总词数,alpha 是文档-主题的Dirichlet先验参数。这部分对应公式中的 (nm,k−i+α)/(nm−i+Kα)。其直观含义是:如果当前文档中已经有很多词属于主题 K,那么当前词属于主题 K 的概率也会相应增加。
计算出未归一化的概率分布数组 p 后,代码采用了轮盘赌算法进行采样。首先通过循环将概率数组转化为累积概率分布,然后生成一个 [0,1) 之间的随机数 u,通过比较 u 与累积概率的大小,确定最终选中的主题索引。这种方法能够高效地从离散概率分布中进行抽样,保证了采样过程既符合数学原理,又具备计算效率。
目标: 对文档m中的第n个词,采样其主题 z_mn
后验概率:
p(zi = k | z(-i), w) ∝ p(w_i | zi=k, z(-i), w_(-i)) × p(zi=k | z(-i))
展开为:
(n^w_{k,w_i} + β) (n^d_{m,k} + α)
p(z_i=k | ...) = ───────────────── × ─────────────────
(n^w_k + V×β) (n^d_m + K×α)在上面的公式中:
- n^w_{k,w_i} : 词w_i分配给主题k的次数(不含当前位置)
- n^w_k : 主题k的总词数
- n^d_{m,k} : 文档m中主题k的词数
- n^d_m : 文档m的总词数
- V : 词汇表大小
- K : 主题数
' Gibbs采样核心代码
Private Shared Function gibbs_sampling(topic As Integer, m As Integer,
ByRef nw As Integer(), ByRef nd As Integer(),
ByRef nwsum As Integer(), ByRef ndsum As Integer(),
ByRef gibbs_pars As gibbs_pars) As Integer
' 计算每个主题的概率
Dim p = New Double(gibbs_pars.K - 1) {}
For K As Integer = 0 To gibbs_pars.K - 1
' ★★★ 核心公式 ★★★
p(K) = (nw(K) + gibbs_pars.beta) / (nwsum(K) + gibbs_pars.voca_size * gibbs_pars.beta) _
* (nd(K) + gibbs_pars.alpha) / (ndsum(m) + gibbs_pars.K * gibbs_pars.alpha)
' └─────────────────────────────────────────────────────────────────────────┘
' 这就是上面的条件概率公式!
Next
' 累积概率(用于轮盘赌采样)
For K As Integer = 1 To p.Length - 1
p(K) += p(K - 1)
Next
' 随机采样
Dim u As Double = randf.NextDouble * p(gibbs_pars.K - 1)
topic = 0
Do While topic < p.Length - 1
If u < p(topic) Then Exit Do
topic += 1
Loop
Return topic
End Function【多项式采样方法 - 轮盘赌法】
示例: 3个主题的概率分布
原始概率: [0.3 0.5 0.2]
累积概率: [0.3 0.8 1. ]
采样过程:
- 生成随机数 u = 0.2881
- 找到第一个使 u < p_cumulative[k] 的k
- 选中的主题 = 0
参数估计 (Theta 和 Phi)
当Gibbs采样过程迭代足够次数并收敛后,算法需要根据最终的采样状态来估计模型的参数,即文档-主题分布 θ 和主题-词分布φ。在代码中,这一过程通过 Theta 和 Phi 两个只读属性以及 update_params 方法来实现。
参数估计基于极大似然估计的思想,并结合了贝叶斯平滑。对于文档 m 中主题k 的概率θmk ,其计算公式为 (nm,k+α)/(nm+Kα)。在代码的 Theta 属性 Get 方法中,这对应于 lTheta(m)(K) = (nd(m)(K) + alpha) / (ndsum(m) + K * alpha)。这里的 nd(m)(K) 是文档 m 中被分配给主题 k 的词数,alpha 作为先验计数,防止了零概率事件的发生。这一参数矩阵揭示了每篇文档的主题构成,是文档分类或聚类的基础。
对于主题 k 中词w 的概率φkw ,计算公式为 (nk,w+β)/(nk+Vβ) 。在代码的 Phi 属性中,对应 lPhi(K)(w) = (nw(w)(K) + beta) / (nwsum(K) + V * beta)。nw(w)(K) 是词 w 被分配给主题k 的次数。φ 矩阵是主题模型的核心产出,它量化了每个词对每个主题的贡献度。在 LdaInterpreter 类中,利用这个矩阵,我们可以通过排序概率值提取出每个主题下概率最高的词汇,从而实现主题的语义解释。
为了提高估计的稳健性,代码引入了样本累积平均机制。如果在配置中设定了 SAMPLE_LAG,系统会在预热期后的特定迭代轮次调用 update_params 方法。该方法将当前状态的 θ 和 φ 累积到 thetasum 和 phisum 中。最终的参数输出是多次采样结果的平均值,这种做法有效地降低了单次采样带来的随机波动,使得模型参数更加稳定可靠。代码通过 numstats 变量记录采样的次数,确保最终的均值计算准确无误。
Gibbs LDA提取基因组代谢主题信息
结果可视化
- 单细胞视角下的微生物基因组代谢酶嵌入分析 - 2026年2月25日
- 基因组代谢酶层级嵌入 - 2026年2月23日
- 基因组功能吉布斯LDA主题建模 - 2026年2月23日

No responses yet